SQL GROUP BY and HAVING Clause with Examples
- MikeBennyhoff
- Mar 2, 2023
- 5 min read

In T-SQL, GROUP BY is a clause used to group rows of data based on one or more columns in a table. The GROUP BY clause is typically used with aggregate functions, such as SUM, AVG, MAX, MIN, and COUNT, to calculate summary statistics for each group of rows.
The GROUP BY clause divides the rows returned by a query into groups, based on the values in one or more columns. For each group, the aggregate functions are applied, and the result of count function is returned as a single row. This allows you to summarize the data and gain insights into trends or patterns within the data.
Group b y SQL Syntax
The basic syntax used for using GROUP BY in T-SQL is as follows:
SELECT column_name1, column_name2, ..., aggregate_function(column_name)
FROM table_name
WHERE condition
GROUP BY column_name1, column_name2, ...;Here's a breakdown of each component:
SELECT:
Specifies the columns to retrieve from the table. We can include aggregate functions in the select statement to perform calculations on the result set of data.
FROM:
Specifies the name of each column names the table to retrieve data from.
WHERE:
Filters the data based on a specified condition. This is optional.
GROUP BY:
Specifies the columns to group the data by. We can group by grouping column by one or more columns to summarize the results based on those columns.
Aggregate_function: Performs a calculation on a single column of data. Examples of aggregate functions include SUM, COUNT, AVG, MIN, and MAX.
Note that when using GROUP BY, any column in the SELECT statement that is not included in the column name the GROUP BY clause must be an aggregate function.
The following example uses uses GROUP BY in T-SQL:
SELECT department, AVG(salary) AS avg_salary
FROM employees
WHERE State = 'CA'
GROUP BY department;GROUP BY clause One Or More Columns in T-SQL:
Let's say we have a table called "orders" that contains information about customer orders. The table has the following columns:
We can create this table using the following SQL code:
CREATE TABLE orders (
order_id int PRIMARY KEY,
customer_id int,
order_date datetime,
total_amount decimal(10,2)
);We can then insert some sample data into the table using the following INSERT statements:
INSERT INTO orders (order_id, customer_id, order_date, total_amount)
VALUES (1, 1001, '2022-01-01', 50.00),
(2, 1002, '2022-01-01', 75.00),
(3, 1001, '2022-01-02', 100.00),
(4, 1003, '2022-01-03', 25.00),
(5, 1002, '2022-01-04', 150.00),
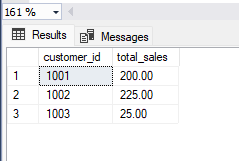
(6, 1001, '2022-01-05', 50.00);Now that we have some sample data in our "orders" table, we can use the GROUP BY clause to summarize the data based on different criteria. For example, let's say we want to find the total number of sales by customer. The following example uses shows by by with one column:
SELECT customer_id, SUM(total_amount) as total_sales
FROM orders
GROUP BY customer_id;The result of this query would be:
When To Use Group By
We can use the GROUP BY clause whenever we want to group and summarize data based on more than one column or more columns. Some common scenarios where GROUP BY is useful include:
Calculating totals or averages for each group
Finding the minimum or maximum value for each group
Counting the number of rows in each group
Grouping data for reporting or analysis purposes.
What is Having?
HAVING is a clause in T-SQL that is used in conjunction with the GROUP BY clause to filter groups group rows based only on a condition. The HAVING clause is similar to the WHERE clause, but it is used to filter groups instead of individual rows.
For example, let's say we have the "orders" table from the previous example, and we want to find duplicate names of the customers who have placed more than $200 in orders. We can use the result set following SQL code:
SELECT customer_id, SUM(total_amount) as total_sales
FROM orders
GROUP BY customer_id
HAVING SUM(total_amount) > 200;The result of this query would be:
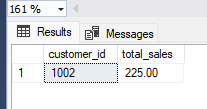
In this example, the GROUP BY clause is used to group the rows in the "orders" table by customer_id, and the SUM function is used to calculate the total sales for each customer. The HAVING clause is used to filter the results and only return rows affected customers whose total sales are greater than $200.
We would use the HAVING clause whenever we want to filter groups based on a condition. Some common scenarios where HAVING is useful include:
Filtering groups based on aggregate values (e.g. total sales, average price)
Finding groups that meet specific criteria (e.g. customers who have placed more than X orders, products with more than Y units sold)
Filtering data for reporting or analysis purposes.
It's important to note that the HAVING clause is only used in conjunction with the GROUP BY clause, and it is evaluated after the groups have been formed. This means that the HAVING clause can only reference columns same values that are part of the same GROUP BY clause or aggregate functions.
GROUP BY Clause With JOIN In SQL
To use GROUP BY with a JOIN in T-SQL, we can join multiple tables together and then group the results by one or more columns. Let's say we have an additional table called "customers" that contains information about each customer, including their name and address.
We can create this table using the following SQL code:
CREATE TABLE customers (
customer_id int PRIMARY KEY,
customer_name varchar(50),
customer_address varchar(100)
);We can then insert some sample data into the table using the following INSERT statements:
INSERT INTO customers (customer_id, customer_name, customer_address)
VALUES (1001, 'Alice', '123 Main St.'),
(1002, 'Bob', '456 Oak St.'),
(1003, 'Charlie', '789 Maple St.');
Now that we have a "customers" table, we can join it with the customers group or "orders" table using the customer_id column, and then group the results by customer name. Here's an example SQL query:
SELECT c.customer_name, SUM(o.total_amount) as total_sales
FROM customers c
INNER JOIN orders o ON c.customer_id = o.customer_id
GROUP BY c.customer_name;
The result of this query would be:
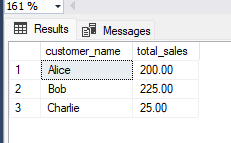
In this example, we use the MAX function to find employees table with the highest total sale amount for each customer, the MIN function to find the lowest total sale amount for each customer, and the SUM function to find the total sales for each customer. We group the results by customer name using the GROUP BY clause, and join the "customers" table with country customers group the "orders" table using the customer_id column.
Using aggregate functions with GROUP BY allows us to perform calculations on the data and summarize the output results based on one or more columns. This can be useful for data analysis and reporting purposes.
Group By With Multiple Columns
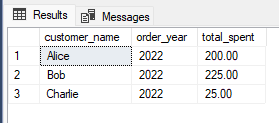
here's an example T-SQL query that groups collect data by two columns using the sample tables and data:
SELECT c.customer_name, YEAR(o.order_date) as order_year, SUM(o.total_amount) as total_spent
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
GROUP BY c.customer_name, YEAR(o.order_date);
This query groups the orders by the customer's name and the year of the order date, and then calculates the total amount spent by each customer in each year. The YEAR() function extracts the year component from the order date.
The output of this query would be:


Comments